

A recurring theme among our posts has been the never-ending proliferation of data: As more devices get smart and connect to dispersed networks, they create new streams of data that IT organizations are confronted with handling.
Smart organizations are realizing the value inherent in this new data – but how do they leverage it without the burdensome work of extracting it into a data warehouse? This is where an abstracted data architecture comes in, allowing organizations to analyze data while it still resides in the cloud.
Building blocks for abstracted data architectures
What are the components necessary to build abstracted data architectures? By nature, abstracted data architectures must leverage the separation between compute and storage as a benefit rather than a challenge. Utilizing low-cost storage services by spinning up separate compute engine services to analyze the data, without moving it all into a separate data warehouse, is one approach. This can be done both with data in the cloud and on-premises, through the deployment of cloud-native architecture.
This approach has rapidly gained popularity, with 71% of the 451 Alliance indicating its use in their organization within the next two years.
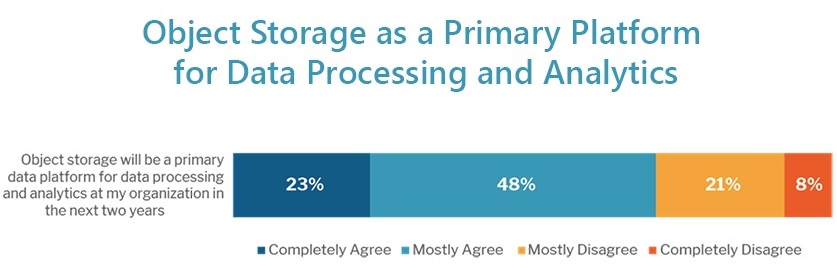
Abstracted data architectures also possess compute engine services to analyze the data in object storage. For example, that analysis could be performed via a Hadoop/Spark service spun up to run against raw data in cloud storage, such as Amazon EMR, Azure Databricks or Google Cloud Dataproc.
Another option, particularly for SQL-based analytics, is using a data-warehousing interface to access curated data sets in the cloud storage layer, such as Google BigQuery, Snowflake, Actian Avalanche, Yellowbrick, Cloudera Data Warehouse, Teradata Vantage or Amazon Redshift Spectrum.
These are but two of many options for data analysis in cloud storage:
- Organizations can query data using Hadoop/Spark services, data-warehouse services or SQL query engines.
- Organizations can create virtual data sets to more easily interact with the data.
Operational efficiency should be top-of-mind
Considerations for abstracted data architectures should be on howto build them, as well as how to make them run efficiently. While one individual data query may be completed in a reasonable amount of time on a given platform, large-scale deployments of many individual queries are a different story.
Vendors such as Scale, Kyligence and Kyvos Insights help organizations to preprocess data and create virtual datasets to add efficiency to data analysis. They can also create a semantic model, which outlines standard business definitions that can be applied across all data, even if it is accessed using multiple different business intelligence and virtualization tools for multiple use cases.

Cloud Maturity Brings Organizational IT Change
Looking at how varied data sources can be across networks, abstracted data architectures need the ability to connect and analyze data from disparate datasets. One example is found in Google BigQuery, which enables federated querying of data in other Google Cloud databases, as well as Apache ORC and Parquet files in cloud storage.
Query federation is also available at the analytics acceleration layer. For example, AtScale has added query federation to its offering by federating its adaptive cache functionality, allowing users to create OLAP cubes to query and combine data from multiple separate databases without moving the data from one environment to another.
The design possibilities are endless
There are many ways organizations can build abstracted data architectures. Just as there are many ways to crack a nut, there are many ways to make an abstracted data architecture a reality.
For example, Alluxio’s data orchestration platform doesn’t neatly fit into any of the categories above, but is used by enterprises to accelerate analytics and to orchestrate the separate compute and storage layers of an abstracted data architecture in both single and multicloud deployments.
In brief, as this model for data handling and analysis continues to surge in popularity, expect to see many more offerings and technologies that help facilitate it in new ways.
Want insights on cloud computing trends delivered to your inbox? Join the 451 Alliance.